Robots.txt-filen är en av de mest grundläggande, men ändå kritiska komponenterna i en webbplats SEO-strategi. Dess huvudsakliga funktion är att kommunicera med webb-crawlare och ge dem instruktioner om vilka delar av din webbplats de får och inte får indexera. Korrekt användning av robots.txt kan förbättra din webbplats crawlbarhet och indexering, medan misstag kan leda till oavsiktlig blockering av viktiga sidor från sökmotorernas index. Här utforskar vi bästa praxis för att hantera din robots.txt och lyfter fram de vanligaste felen som webbplatsägare bör undvika.
Bästa Praxis för Robots.txt
- Använda “Disallow” med Försiktighet: Använd kommandot “Disallow” endast för de sidor eller resurser du aktivt vill hålla borta från sökmotorernas indexer. Överanvändning kan leda till att värdefullt innehåll utesluts från sökresultaten.
- Tillåta Viktiga Resurser: Se till att tillåta åtkomst till CSS-, JavaScript- och bildfiler som behövs för att korrekt rendera dina sidor. Detta hjälper sökmotorer att korrekt indexera din webbplats utseende och funktioner.
- Använd “Allow” för Prioriterade Sidor: Även om “Allow”-direktivet inte är nödvändigt, kan det hjälpa till att klargöra din avsikt, särskilt om du har en komplex webbstruktur eller använder många “Disallow”-regler.
- Undvik att Blockera Interna Söksidor: Även om det kan tyckas logiskt att blockera interna sökresultatsidor för att undvika duplicerat innehåll, kan detta förhindra att sökmotorer upptäcker nytt innehåll på din webbplats.
- Kontrollera Din Robots.txt Regelbundet: Webbplatser förändras över tid, och vad som var relevant att blockera för ett år sedan kanske inte längre är det idag. Regelbunden granskning säkerställer att din fil fortfarande återspeglar din nuvarande webbstruktur och innehållsstrategi.
Vanliga Fel
- Blockera Allt av Misstag: En felplacerad “Disallow: /” kan blockera hela din webbplats från att bli indexerad. Ett enkelt skrivfel kan ha stora konsekvenser.
- Glömma att Tillåta Crawlning av Viktiga Resurser: Att oavsiktligt disallowa CSS- och JS-filer kan hindra sökmotorer från att korrekt förstå och rendera dina sidor, vilket negativt påverkar din ranking.
- Försumma att Uppdatera Efter Webplatsändringar: Om du genomför större omstruktureringar av din webbplats utan att uppdatera din robots.txt, kan du oavsiktligt blockera nytt innehåll från att indexeras.
- Använda Robots.txt för att Förhindra Duplicerat Innehåll: Robots.txt bör inte användas för att hantera duplicerat innehåll. Använd istället kanoniska länkar eller 301-omdirigeringar för detta ändamål.
För en djupare förståelse för webb crawlare, och hur de interagerar med din webbplats, rekommenderas att läsa vår tidigare artikel. Där utforskar vi nyanserna av hur sökmotorers crawlare navigerar genom din webbstruktur och hur du kan optimera din webbplats för bättre synlighet och indexering.
Exempel på en robots.txt fil
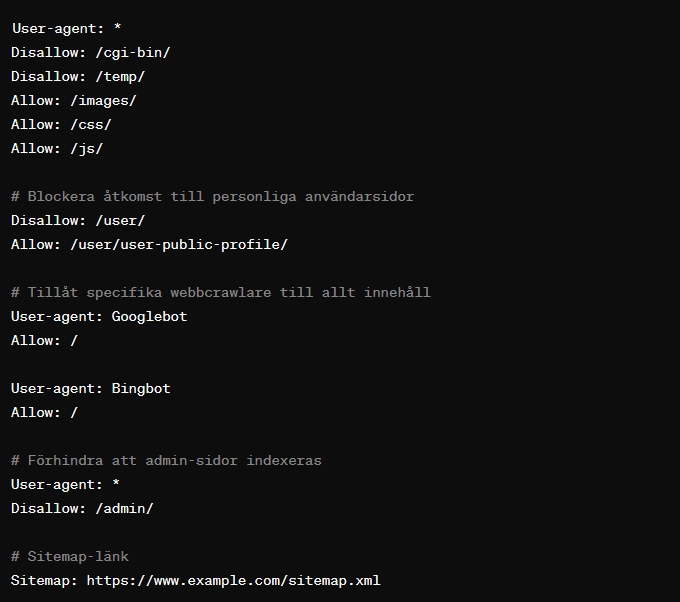
I detta exempel:
User-agent: *anger att följande regler gäller för alla webbcrawlare.Disallow: /cgi-bin/,Disallow: /temp/, ochDisallow: /user/anger kataloger som inte får besökas av crawlare. Det betyder att allt innehåll i dessa kataloger inte kommer att indexeras.Allow: /images/,Allow: /css/, ochAllow: /js/specifierar att trots generellaDisallow-regler, ska dessa kataloger vara tillgängliga för crawlare. Detta är viktigt för att säkerställa att webbplatsens stilmallar och skript kan indexeras, vilket bidrar till korrekt rendering och förståelse av sidorna.- Specifika regler för
GooglebotochBingbottillåter full åtkomst till hela webbplatsen, vilket överstyr de allmännaDisallow-reglerna. Disallow: /admin/underUser-agent: *blockerar alla crawlare från att indexera admin-katalogen.- Slutligen anger
Sitemap: https://www.example.com/sitemap.xmlplatsen för webbplatsens sitemap, vilket hjälper sökmotorer att effektivt hitta och indexera sidor.
Det är viktigt att noggrant överväga vad som ska inkluderas i din robots.txt-fil för att undvika att oavsiktligt blockera viktig innehåll från att bli indexerat. Korrekt användning av Disallow och Allow kan göra en stor skillnad i hur din webbplats presenteras i sökresultaten.
Genom att följa dessa riktlinjer och undvika vanliga misstag kan du säkerställa att din robots.txt-fil effektivt styr sökmotorernas crawlare på ett sätt som gynnar din webbplats långsiktiga SEO-strategi.
